2025年6月,人工智能领域顶级会议ICCV公布了2025年的论文录用结果,深圳北理莫斯科大学粤港澳情感智能与普适计算联合实验室师生投稿的3篇文章顺利入选,文章涉及到多媒体分析、联邦学习、图像内容安全保护等研究领域。
ICCV 的全称是国际计算机视觉会议(International Conference on Computer Vision),每两年举办一次,是计算机视觉领域的顶级会议,被中国计算机学会 CCF 推荐为 A 类国际学术会议。本届会议共收到 11,239 篇有效投稿,最终接收 2,698 篇,接收率为 24%。会议将于 2025 年 10 月 19 日至 23 日在美国夏威夷檀香山举行。
入选论文介绍
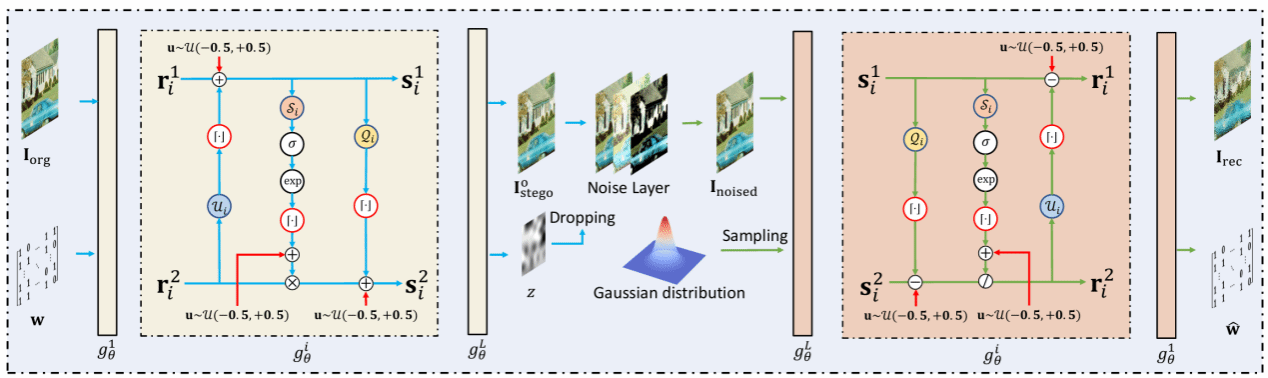
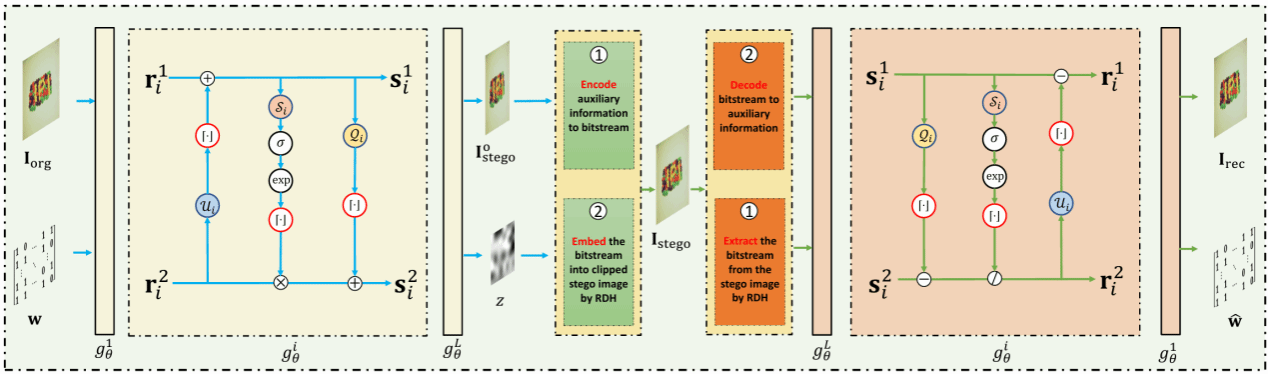
1.论文题目:Learning Robust Image Watermarking with Lossless Cover Recovery
摘要:
水印技术作为一种可追溯的身份验证技术,已被广泛应用于图像版权保护中。然而,大多数现有的水印方法通过向载体图像中添加不可去除的扰动来嵌入水印,从而造成永久性的图像失真。为了解决这一问题,我们提出了一种新颖的水印方法,称为CRMark。CRMark 在无损信道中能够无损地恢复载体图像和水印,在有损信道中也支持鲁棒的水印提取。CRMark 利用一种整数可逆水印网络,在载体图像-水印对与含水印图像之间建立无损可逆映射。在训练阶段,CRMark 采用编码器-噪声层-解码器结构,以增强其对失真的鲁棒性。在推理阶段,CRMark 首先将载体图像-水印对映射为一个溢出的含水印图像和一个潜变量;随后,将溢出像素和潜变量无损压缩为辅助比特流,并通过可逆信息隐藏技术将其嵌入到裁剪后的含水印图像中。在提取阶段,于有损信道中,带噪声的含水印图像可以直接通过 iIWN 逆向映射提取水印;而在无损信道中,首先利用可逆信息隐藏技术恢复潜变量和溢出图像,再通过 iIWN 提取水印。大量实验结果表明,CRMark 在无损信道中可以完美恢复原始图像和水印,同时对常见的图像失真具有良好的鲁棒性。
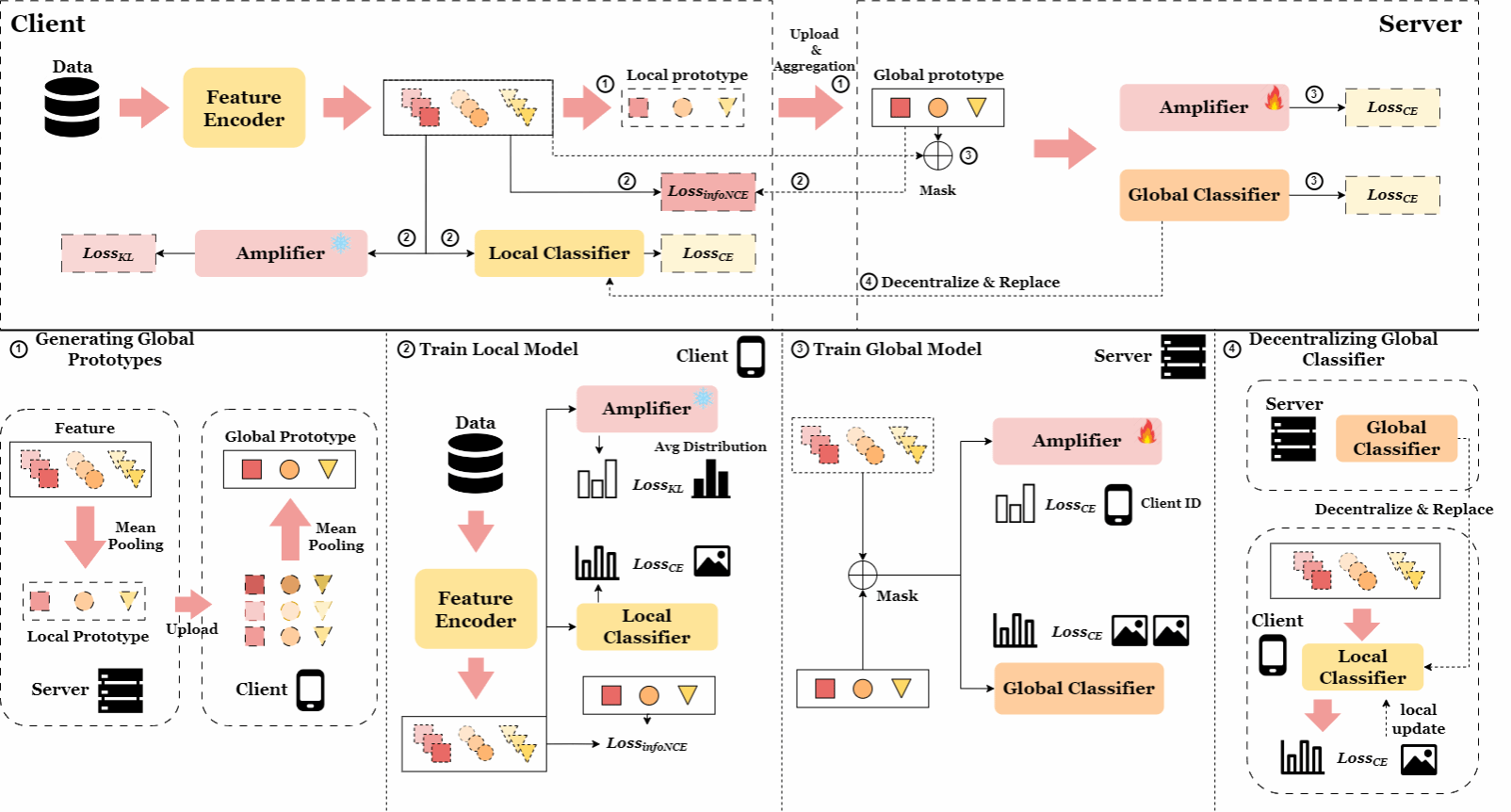
2.论文题目:FedPall: Prototype-based Adversarial and Collaborative Learning for Federated Learning with Feature Drift
摘要:
联邦学习(Federated Learning,FL)使多个参与方能够在保持数据隐私的前提下,通过集中式服务器协同训练一个全局模型。然而,当各参与方使用来源不同的数据集训练本地模型时,数据异质性会显著削弱全局模型的性能。在各种数据异质性问题中,特征漂移(即各参与方之间的特征空间差异)在真实数据中十分常见,但仍缺乏深入研究。特征漂移会干扰客户端的特征提取过程,从而导致特征提取能力和分类性能下降。为了解决联邦学习中的特征漂移问题,我们提出了 FedPall 框架,该框架结合了基于原型的对抗学习来统一特征空间,并通过协同学习机制增强特征中的类别信息。此外,FedPall 还利用由全局原型与本地特征混合生成的特征,从全局视角提升分类器对类别相关信息的感知能力。我们在三个具有代表性的特征漂移数据集上进行了评估,结果表明,在处理特征漂移数据的联邦学习任务中,FedPall 在分类性能上始终表现优越。
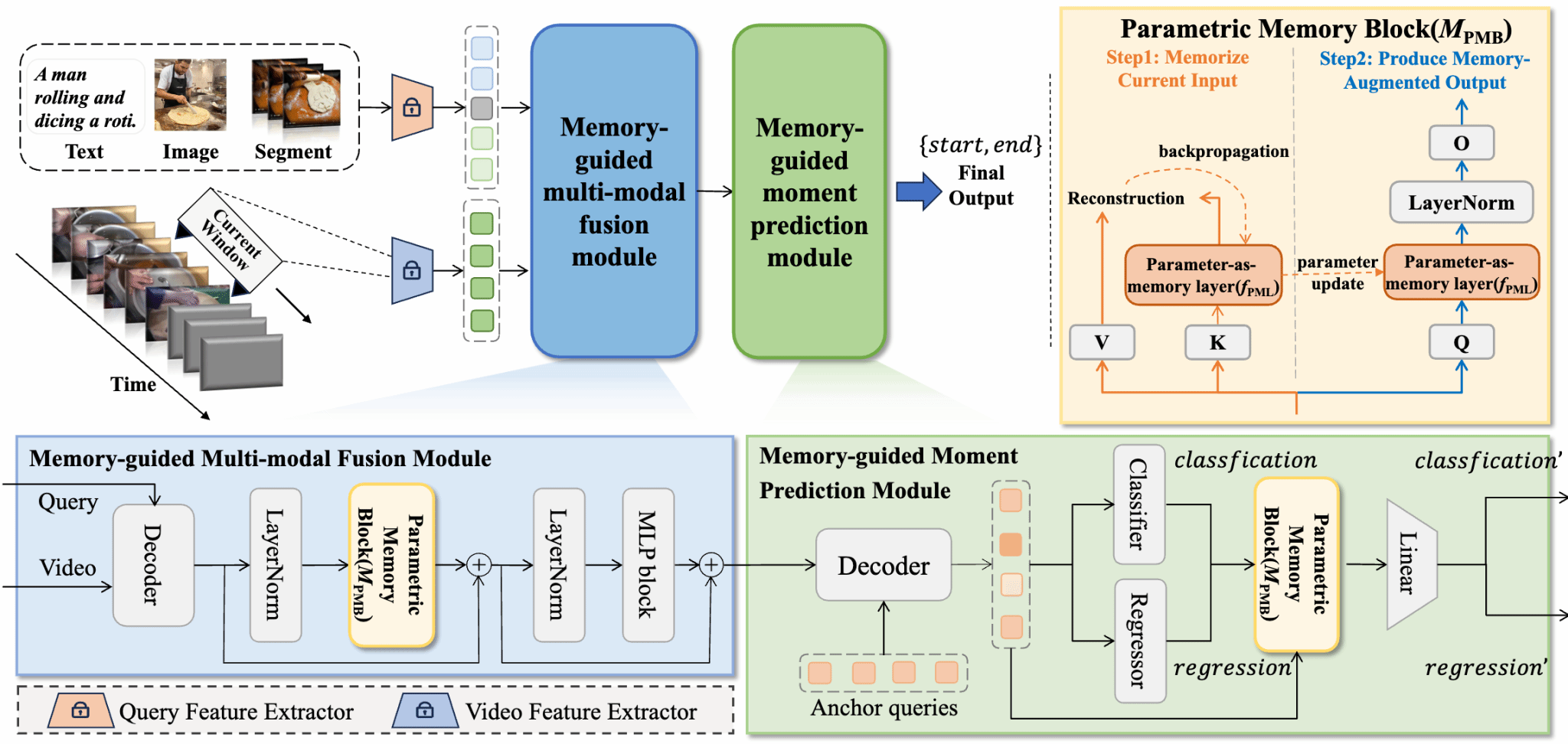
3.论文题目: OVG-HQ: Online Video Grounding with Hybrid-modal Queries
摘要:
视频定位(Video Grounding, VG)任务的核心在于根据查询(通常为文本形式)在视频中定位特定的片段。然而,许多场景(如流媒体视频定位或使用视觉线索进行查询)无法被传统的VG任务很好地反映,这些场景需要在线处理能力,并支持输入多样化的模态,如图像或视频片段。为填补这一空白,我们提出了一项名为基于混合模态查询的在线视频定位(Online Video Grounding with Hybrid-modal Queries, OVG-HQ)的新任务。该任务支持在视频流中使用混合模态查询(包括单模态和多模态查询,例如文本、图像、视频片段及其组合)进行在线片段定位。这项新任务带来了两个主要挑战:在线设置下的上下文信息有限以及模态不平衡(即主导模态会掩盖弱势模态)。为克服这些挑战,我们提出了一个统一的框架OVG-HQ-Unify。该框架包含一个参数化记忆模块(Parametric Memory Block),用于动态保留历史上下文信息;以及一种跨模态蒸馏策略,用于指导非主导模态的学习。由于缺乏合适的数据集,我们构建了QVHighlights-Unify数据集,这是一个扩展了多模态查询的数据集。同时,我们引入了新的评估指标,即在线召回率(oR@n, IoU=m)和在线平均精度均值(online mean Average Precision, omAP),以评估模型的准确性和效率。实验结果表明,我们的OVG-HQ-Unify模型优于现有模型,为在线、混合模态视频定位提供了一个鲁棒的解决方案。





