2024年12月,人工智能领域顶级会议AAAI公布了2025年的论文录用结果,深圳北理莫斯科大学粤港澳情感智能与普适计算联合实验室师生投稿的六篇文章顺利入选,文章涉及到情感计算、自动驾驶、自然语言处理等多个研究领域。
AAAI的全称是国际人工智能协会(Association for the Advancement of Artificial Intelligence),每年举办的AAAI年会是人工智能领域的顶级会议,中国计算机学会CCF推荐的A类国际学术会议。本次会议共有12,957篇投稿,接收率仅为 23.4%。会议将于2025年2月25-3月4日在美国宾夕法尼亚州费城召开。
入选论文介绍
1.论文题目:Understanding Emotional Body Expressions via Large Language Models

摘要:
基于肢体动作的情感识别在人机交互中至关重要。然而,现有方法主要聚焦于情感分类,不能进一步提供文本解释来验证其分类的合理性。在本文中,我们提出了一个由大语言模型驱动的情绪-动作解释器(EAI-LLM),它不仅可以识别情绪,还可以针对输入的3D骨架序列来生成相应的文本解释。具体而言,我们将骨架序列视为一种特殊的语言,提出一种多粒度骨架序列标记器。该标记器可以将来自异构数据集的骨架序列统一提取时空标记和语义标记,利用LLMs广泛的背景知识和语言处理能力来解决异构数据集联合训练的挑战,从而显著提高识别精度,并生成细粒度的情感描述。实验结果表明,在LLMs背景知识的支持下,我们的EAI-LLM模型可以在有限标记的骨架序列上进行微调,生成详细的情绪描述,且识别精度与现有方法相当甚至更佳。
2.论文题目:Dual-View Interaction-Aware Lane Change Prediction for Autonomous Driving
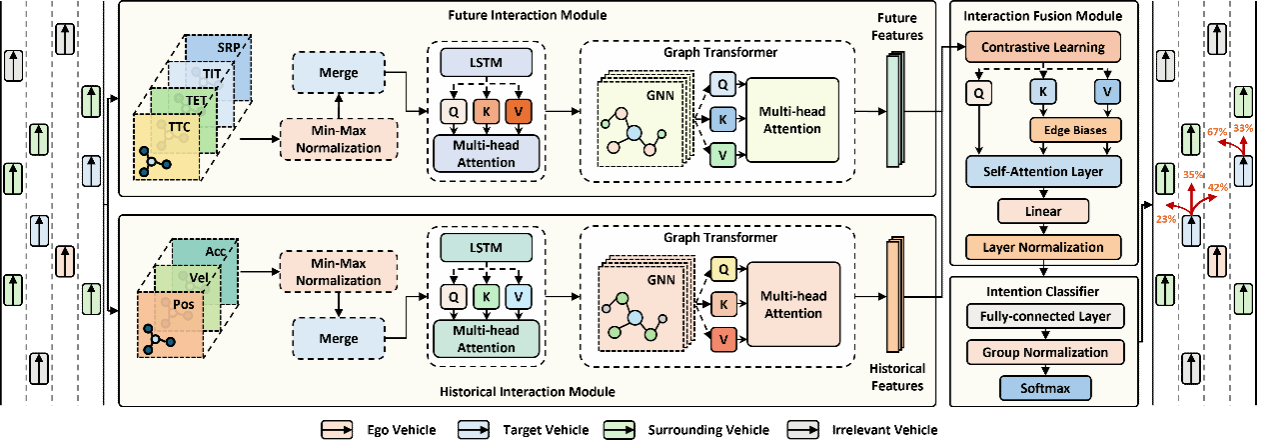
摘要:
随着人工智能技术的不断发展,我们正迈向自动驾驶车辆广泛部署的关键时刻。然而,由此带来的混合自主交通环境为自动驾驶车辆带来了严峻挑战,尤其是对周围有人驾驶车辆变道意图的准确预测,这对于保障自动驾驶车辆的安全至关重要。现有的变道预测模型主要集中于捕捉单辆车辆运动动态的时间变化,但忽视了车辆间的交互关系,这在复杂的变道场景中限制了其预测能力,导致性能不理想。此外,目前的交互感知方法无法对车辆之间的未来交互进行建模,容易产生不合理的预测结果,可能引发车辆碰撞。针对上述问题,我们提出将感知安全的概念融入未来交互建模,并设计了一种双视角交互感知变道预测模型。在两个真实数据集上的评估结果表明,该模型在分类能力上相比表现最优的基线模型平均提升了11.7%-12.4%,在预测能力上提升了75.6%-95.7%。通过消融研究和对未来交互建模的分析,证明了我们模型在从驾驶安全视角解释变道场景方面的优势,并实现了社会化感知的变道预测。
3.论文题目:Learning to Generate Gradients for Test-Time Adaptation
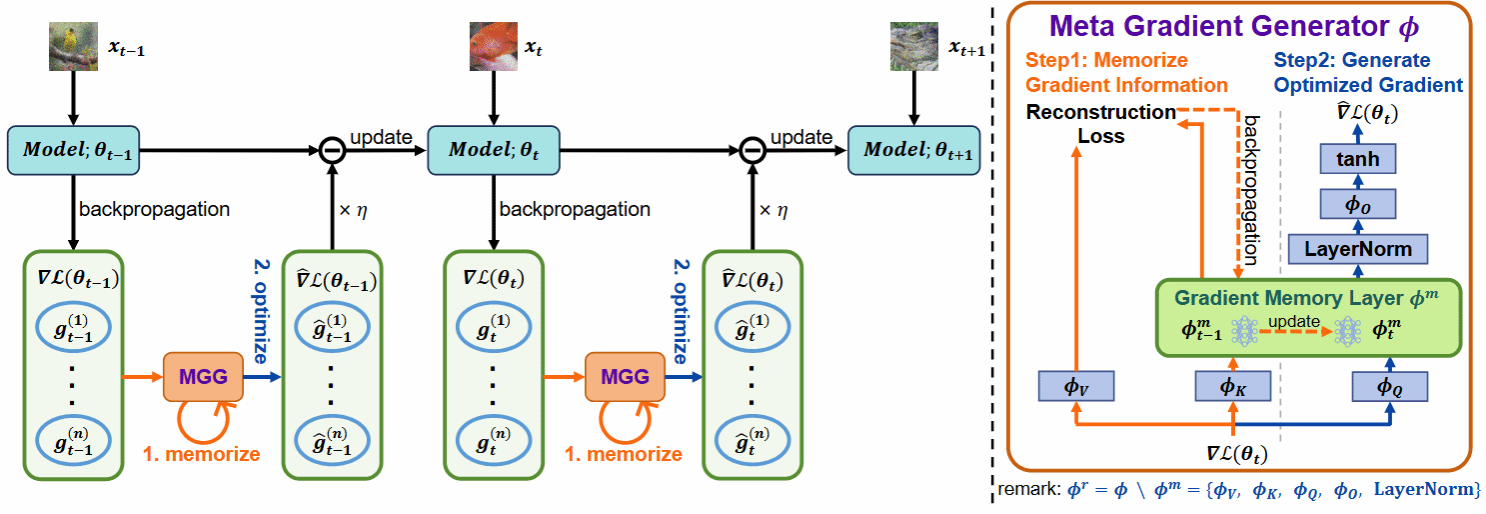
摘要:
测试时自适应(TTA)旨在使用未标记的测试数据在线微调已训练好的模型,以适应新环境或分布外的数据,在实际场景中表现出广泛的应用潜力。然而,在这个优化过程中,像熵最小化这样的无监督学习目标经常会遇到嘈杂的学习信号。这些信号产生不可靠的梯度,阻碍了模型快速收敛到最优解的能力,并在优化过程中引入了显著的不稳定性。在本文中,我们试图从优化器设计的角度解决这些问题。与之前使用 SGD 等手动设计的优化器的TTA方法不同,我们采用一种学习优化的方法来自动学习一个称为元梯度生成器(MGG)的优化器。具体来说,我们的目标是让MGG在在线优化过程中有效利用历史梯度信息来优化当前模型。为此,在MGG中,我们设计了一个轻量级且高效的序列建模层——梯度记忆层。它利用自监督重构损失将历史梯度信息压缩为网络参数,从而在长期适应过程中实现更好的记忆能力。我们只需要少量未标记的样本来预训练MGG,然后可以部署训练后的MGG来处理未见过的样本。ImageNet-C/R/Sketch/A上的实验结果表明,我们的方法以更少的更新次数、更少的数据和更短的自适应时间超越了当前最先进的方法。与之前的SOTA方法SAR相比,我们在 ImageNet-C上实现了7.4%的准确率和4.2倍的适应速度提升。
4.论文题目:Training on the Benchmark Is Not All You Need

摘要:
大规模语言模型(LLMs)的成功在很大程度上依赖于在预训练阶段学习到的大量预训练数据。预训练过程及其数据的不透明性导致许多基准测试的结果变得不可靠。如果任何模型已经在基准测试集上进行了训练,这可能会严重阻碍该领域的健康发展。为了自动化和高效地测试大规模语言模型的能力,许多主流基准测试采用了多项选择题的格式。由于多项选择题选项内容的交换不影响问题本身的含义,我们提出了一种基于这一特性的简单有效的数据泄露检测方法。具体来说,我们通过打乱数据中选项的内容来生成相应的衍生数据集,然后基于模型在这些衍生数据集上的对数概率分布检测数据泄露。如果在对数概率的集合中存在最大值或异常值,便表示数据发生了泄露。我们的方法能够在黑盒条件下工作,无需访问模型的训练数据或权重,有效识别模型预训练数据中来自基准测试集的数据泄露,包括正常情况以及选项可能被有意或无意地打乱的复杂情况。通过基于两种大规模语言模型和基准设计的实验,我们展示了该方法的有效性。此外,我们还评估了31个主流开源大规模语言模型在四个基准数据集上的数据泄露程度,并对每个基准数据集中的泄露模型进行了排名,发现Qwen家族的大规模语言模型泄露程度最高。
5.论文题目:Multi-Label Few-Shot Image Classification via Pairwise Feature Augmentation and Flexible Prompt Learning
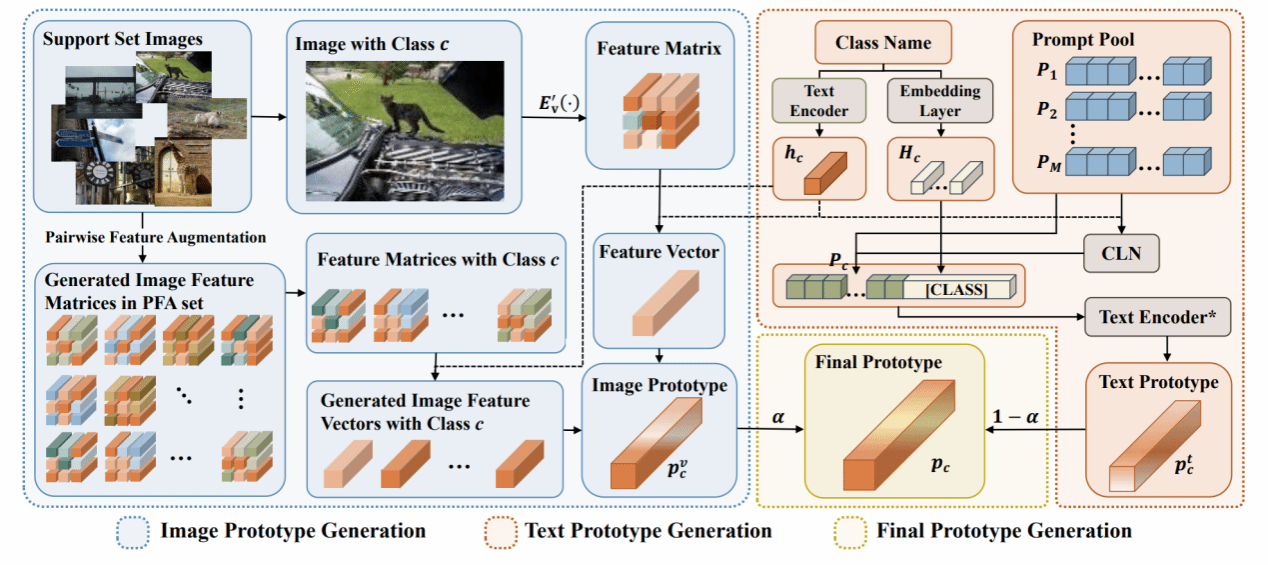
摘要:
由于注释数据有限和类别特异性难以捉摸,多标签少样本图像分类是一项至关重要且极具挑战性的任务。然而,对这一课题的研究仍处于初级阶段,可用的方法很少。现有的方法要么利用数据增强来缓解数据稀缺的问题,要么利用标签特征作为辅助知识来消除不相关类别带来的负面影响,但它们忽视了利用图像区域特征进行数据增强,也忽略了学习适当的文本特征来更好地匹配特定类别的图像特征。此外,这些方法只关注了一个方面,没有同时有效地解决上述两个问题。在本文中,我们介绍了一种新颖的基于原型的多标签少样本图像学习框架,它将成对特征增强和灵活的提示学习结合在一起。具体来说,通过成对特征增强,我们利用支持集中图像的区域特征来生成更多图像特征并构建图像原型,从而缓解了数据稀缺的问题。通过灵活的提示学习,我们自适应地获取特定类别的提示,构建与特定类别图像特征高度匹配的文本原型,从而减轻无关类别的影响。最后,通过自适应可学习参数,我们将图像原型和文本原型合并,得到最终原型,从而为多标签少样本图像分类提供更强大的分类器。广泛的实验结果表明,我们提出的方法可以将基准性能推向更高水平。
6.论文题目:Efficient Language-instructed Skill Acquisition via Reward-Policy Co-Evolution

摘要:
在机器人自主学习领域,高效地通过语言指令获取技能对于减少人工指导至关重要。尽管强化学习方法在很大程度上减轻了人工干预,但设计真实世界任务的奖励函数,尤其是高维机器人控制任务的奖励函数,仍然面临巨大挑战。最近,随着大型语言模型(LLMs)的进步,自动设计奖励函数变得可行。然而,现有方法在评估奖励函数时,往往需要从头开始重新训练策略,这对奖励函数提出了过高的要求,期望其在策略改进的每个阶段——从初始阶段到收敛阶段——都能有效。为了解决这一问题,本文提出了一种新颖的奖励-策略共同演化框架(ROSKA),该框架允许奖励函数和学习策略相互促进、共同演化,从而在每个阶段逐步实现即时改进,最终高效地获取机器人技能。具体而言,奖励演化过程通过将机器人之前最优的奖励函数、任务描述和环境信息转化为文本输入,查询LLMs生成多个奖励函数候选,并确保每轮演化都能带来持续改进。在策略演化方面,我们的方法通过混合历史最优策略和随机策略来生成新的策略种群。结合改进的贝叶斯优化算法,我们的方法能够高效且稳健地识别最具潜力的奖励-策略组合,进而进入下一轮的共同演化。实验结果表明,我们的方法能够在使用更少的训练样本情况下在多种高维机器人技能学习任务中实现了平均95.3%的归一化性能提升,突出了其在提高机器人在复杂环境中的适应性和精确性方面的有效性。通过与稀疏奖励方法、人工设计奖励方法以及传统LLM设计奖励函数方法的比较,ROSKA在所有任务中均展现出卓越的性能,特别是在ShadowHand和FrankaCabinet任务中,分别实现了相对于人工设计奖励的4倍和8倍性能提升。这些结果不仅证明了ROSKA在机器人自主学习领域的巨大潜力,也展示了其在实际应用中的广泛适用性。





